Enterprise-grade synthetic data solutions for privacy-safe analytics and AI.
Replace sensitive datasets with high-utility synthetic data—designed to preserve statistical characteristics while reducing re-identification risk and accelerating delivery.
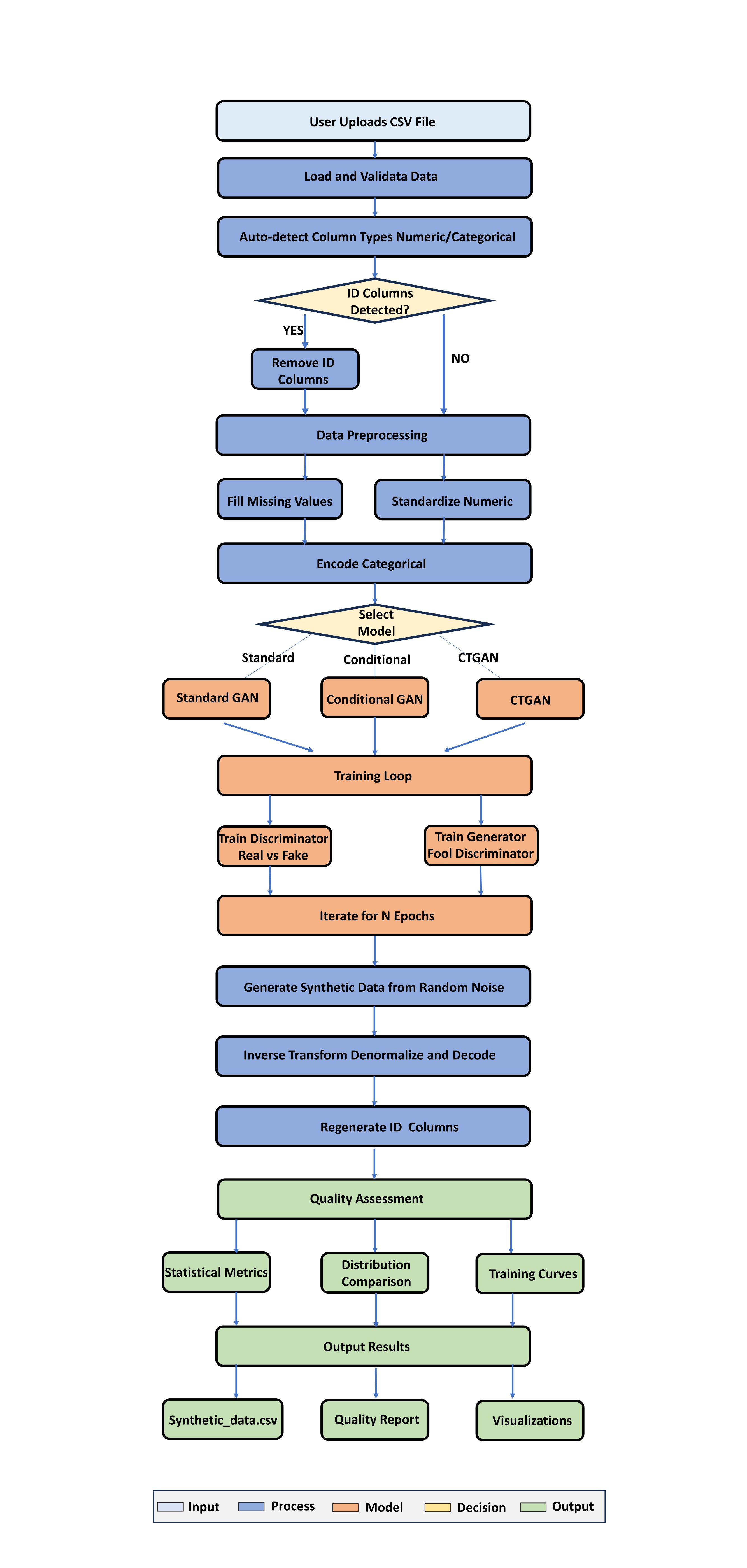
Synthetic Data Workflow
Schema Inference
Completed
Detecting fields, data types, null ratios, cardinality
Constraint Learning
Completed
Ranges, categorical rules, temporal consistency
Distribution Modeling
Running
Marginal distributions, correlations, rare patterns
Privacy Evaluation
Passed
Distance checks, nearest-neighbor leakage, disclosure risk
Utility Validation
98.4% matched
Correlation similarity, downstream performance, drift score
synthetic_data_workflow.py
schema_constraints.yaml
quality_report.json
Synthetic tabular data generation · finance domain
import pandas as pd
from sdv.single_table import CTGANSynthesizer
from sdv.metadata import Metadata
# Load source data
real_data = pd.read_csv("financial_transactions.csv")
# Define metadata
metadata = Metadata.detect_from_dataframe(data=real_data)
# Update constraints
metadata.update_column(
column_name="transaction_amount",
sdtype="numerical"
)
metadata.update_column(
column_name="transaction_type",
sdtype="categorical"
)
metadata.update_column(
column_name="account_age_days",
sdtype="numerical"
)
# Train synthesizer
synthesizer = CTGANSynthesizer(
metadata=metadata,
epochs=300
)
synthesizer.fit(real_data)
# Generate synthetic samples
synthetic_data = synthesizer.sample(num_rows=10000)
# Save output
synthetic_data.to_csv("synthetic_transactions.csv", index=False)
# Evaluate utility
corr_real = real_data.corr(numeric_only=True)
corr_syn = synthetic_data.corr(numeric_only=True)
# Example quality summary
quality_report = {
"column_shape_score": 0.97,
"pair_trend_score": 0.96,
"correlation_similarity": 0.984,
"privacy_leakage_risk": "low"
}
Generation Summary
Rows generated:
10,000
Schema matched:
100%
Correlation similarity:
98.4%
Privacy leakage risk:
Low
Rare pattern retention:
93.1%